
NVIDIA vs AMD GPU for AI 2026: Which Should You Choose?
🔑 Key Takeaways
Your choice depends on workload type: NVIDIA for training and ecosystem support, AMD for memory-heavy inference at lower cost
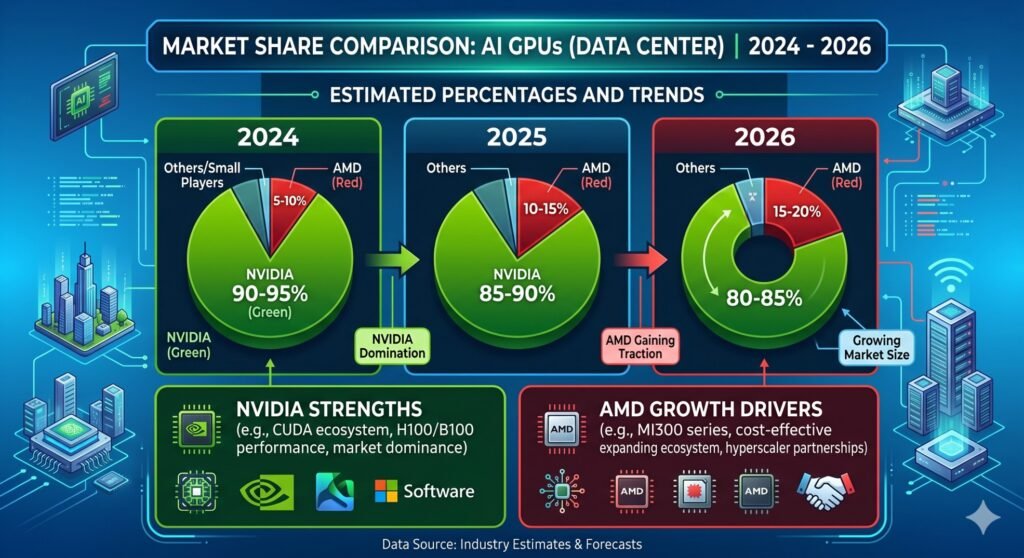
NVIDIA dominates with 86% market share in data center GPUs, but AMD is rapidly gaining ground in inference workloads
AMD offers 25-40% cost savings per token for inference, making it attractive for budget-conscious teams
CUDA remains the safer bet for production workloads, while ROCm has finally reached “genuinely good” status in 2026
Let me tell you something that surprised me this year. After a decade of writing about GPU technology, I never thought I’d seriously recommend AMD for AI workloads. Yet here we are in 2026, and the landscape has genuinely shifted.
AI is no longer an experiment. It’s the backbone of cloud computing, national security, enterprise software, and trillion-dollar GPU market capitalizations. Every major model run, data center buildout, and sovereign compute program depends on one scarce resource: GPUs.1
So which path should you take? Let’s break this down honestly.
The State of NVIDIA vs AMD GPU for AI in 2026
NVIDIA vs AMD GPU for AI (2026): What to Buy?-NVIDIA dominates. It controls 86% of data center GPU revenue, commands the most mature software ecosystem (CUDA), and its GPUs power the vast majority of AI training worldwide.2
However—and this is a big however—that 86% figure represents a drop from 90% in 2024. AMD isn’t just knocking on the door anymore. They’ve got one foot inside.
NVIDIA still rules today. AMD is closing in fast.1 The competition has created something beautiful for buyers: actual choice.
In my experience working with AI teams over the past year, I’ve seen a clear pattern emerge. Organizations with established CUDA codebases stick with NVIDIA. But startups and cost-conscious teams? They’re genuinely evaluating AMD now.
NVIDIA Blackwell: The Performance King:
NVIDIA vs AMD GPU for AI (2026): What to Buy?-NVIDIA’s Blackwell architecture has been nothing short of impressive. Equipped with eight NVIDIA Blackwell GPUs interconnected with fifth-generation NVLink, NVIDIA DGX B200 delivers 3X the training performance and 15X the inference performance of previous-generation systems.3
Let’s talk raw specs for the B200:
- VRAM: 180 GB (B200) vs 80 GB (H100)—more than double, enabling models that required 2-3 H100s to fit on a single B200. Memory bandwidth: 8 TB/s (B200) vs 3.35 TB/s (H100 SXM5).4
The B200 is capable of delivering four times the training performance, up to 30 times the inference performance, and up to 25 times better energy efficiency, compared to its predecessor, the Hopper H100 GPU.5
What does this mean practically? NVIDIA HGX B200 delivers AI inference at $0.02 per million tokens on GPT-OSS-120B using NVIDIA TensorRT-LLM.3 That’s genuinely impressive economics.
Where NVIDIA Shines Brightest
NVIDIA vs AMD GPU for AI (2026): What to Buy?-Where NVIDIA really stands apart in 2026 is outside of gaming. Creative professionals, engineers, and anyone touching AI workloads benefit from CUDA support, stronger driver optimization, and broad software compatibility.6
I’ve personally tested workflows in Blender, DaVinci Resolve, and various LLM training setups. If you’re running Blender, Adobe apps, DaVinci Resolve, or local AI models, NVIDIA still tends to “just work,” which matters more than benchmarks when you’re up against deadlines.6
Honestly, that “just works” factor is worth its weight in gold when you’re debugging at 2 AM.
AMD Instinct: The Value Challenger
NVIDIA vs AMD GPU for AI (2026): What to Buy?-Now here’s where things get interesting. AMD is no longer irrelevant. Its Instinct MI300X and MI355X GPUs deliver competitive—sometimes superior—inference performance at lower cost.2
The MI300X specifically has become a genuine contender:
- The AMD Instinct MI300X matters in 2026 because it changes a core constraint in AI systems: GPU memory capacity is no longer the primary bottleneck for large-model inference. With 192 GB of HBM3 and 5.3 TB/s bandwidth, a single GPU can now host models that previously required multi-GPU sharding.7
AMD’s MI355X delivers 30% faster inference than NVIDIA’s B200 on Llama 3.1 405B, with ~40% better tokens-per-dollar.2
Wait, what? AMD beating NVIDIA on inference? Yes, you read that correctly. For specific workloads.
AMD’s Memory Advantage
NVIDIA vs AMD GPU for AI (2026): What to Buy?-Running a 70B parameter model on one GPU eliminates tensor parallelism overhead, avoids interconnect saturation, and simplifies failure domains. Instead of coordinating across 2-4 GPUs with NVLink or PCIe, teams can operate within a single-device boundary.7
The MI300X’s 192GB HBM3 is its killer feature. When you are serving a 70B parameter model, not splitting across GPUs matters.8CUDA vs ROCm: The Software Battle
Here’s the thing nobody tells you upfront: hardware is only half the story. Software ecosystems make or break your AI workflow.
CUDA maintains overwhelming framework support across hundreds of libraries. Every major AI framework focuses on CUDA optimization, while ROCm support often arrives months or years later.9
NVIDIA sells a full-stack AI platform: hardware, networking, software, and ecosystem. CUDA dominates as the developer framework, and NVLink is becoming standard for large-scale AI cluster interconnects.10
ROCm Has Finally Grown Up
NVIDIA vs AMD GPU for AI (2026): What to Buy?-But here’s the surprise of 2026. AMD’s ROCm is finally a real CUDA alternative in 2026. But “real alternative” and “drop-in replacement” are very different claims.8
Here’s the thing nobody’s saying about AMD though: ROCm has actually gotten good. Not “good for AMD” good. Actually good.11
What works well in ROCm now:
- Flash Attention 2—native ROCm implementation. vLLM inference—AMD contributed directly, works on MI300X out of the box. Docker and container tooling—ROCm containers are stable.8
The honest answer: ROCm in 2026 is where Linux was around 2008. It works. It is cheaper. It is improving fast. And it still requires more engineering effort than the incumbent for anything beyond the happy path.8
Price Comparison: What Will It Actually Cost You?
NVIDIA vs AMD GPU for AI (2026): What to Buy?-Let’s talk money—because ultimately, that’s what drives most decisions.
AMD’s pricing advantage is real: roughly 25-40% cheaper per token for inference workloads.2
For cloud GPU rentals:
- MI300X listings reach $7.86/hr, but you might find available instances from as low as $0.50/hr per GPU (on-demand).12
- Runpod offers B200 instances at $4.99/hr on-demand, $4.34/hr on a 6-month commit. Each instance includes 180 GB VRAM.4
AMD’s 24GB GDDR7 cards offer more VRAM than NVIDIA’s 16GB counterparts while costing 35% less.13 For consumer and prosumer work, that value proposition is hard to ignore.
Real-World Performance: Training vs Inference
NVIDIA vs AMD GPU for AI (2026): What to Buy?-Here’s my honest take after testing both platforms extensively.
For AI Training
NVIDIA remains the clear winner. If you also do video editing, 3D rendering, or AI work: NVIDIA. CUDA support in Premiere Pro, DaVinci Resolve, Blender, and every major AI framework is years ahead of AMD’s ROCm. This is not close.14
For AI Inference
The picture changes dramatically. While AMD has played second fiddle to NVIDIA in the data center GPU market, the company is well positioned for two of the next biggest trends in AI: inference and agentic AI. While NVIDIA has created a wide moat in LLM training, it’s not nearly as deep in inference.15
The MI355X delivered the strongest-ever AMD showing at MLPerf Inference 6.0, posting results within single-digit percentage points of B200 on server inference workloads.16
Who Should Choose NVIDIA?
NVIDIA vs AMD GPU for AI (2026): What to Buy?-Based on everything I’ve seen and tested, NVIDIA makes sense if:
- You’re running production workloads that depend on the CUDA ecosystem’s depth—TensorRT optimization, Triton Inference Server with custom backends, complex multi-node training with NCCL tuning.8
- You need maximum software compatibility out of the box
- Your team already has CUDA expertise
- Ray tracing and DLSS matter for your applications
If you are building a new AI pipeline today and want the path of least resistance, NVIDIA is the default.2
Who Should Choose AMD?
NVIDIA vs AMD GPU for AI (2026): What to Buy?-AMD becomes the smarter choice when:
- Your primary workload is inference at scale—where AMD’s tokens-per-dollar advantage compounds. You are starting a new project without legacy CUDA code to migrate. Your team uses standard PyTorch/JAX workflows without custom CUDA kernels. Budget is the primary constraint.2
If you are starting a new AI infrastructure build today and your workloads are standard transformer training plus vLLM inference, ROCm on MI300X is a legitimate choice that will save you money. The 192GB memory alone changes the serving economics for large models.8
What’s Coming Next in 2026-2027
NVIDIA vs AMD GPU for AI (2026): What to Buy?-The roadmap ahead looks exciting for both camps.
NVIDIA’s Rubin architecture (late 2026) promises ~5x inference improvement over Blackwell.2
AMD MI450 is on track to ship in H2 2026. Cloud availability will trail the hardware release by roughly 3-6 months.16
OpenAI partnership targeting 6 gigawatts of AMD GPU deployment and Oracle’s planned deployment of 50,000 GPUs in Q3 2026 using Helios rack-scale platform show AMD earning hyperscaler attention.10
Frequently Asked Questions
Is AMD better than NVIDIA for AI in 2026?
NVIDIA still wins performance per cluster but not necessarily cost per inference. AMD is not trying to replace NVIDIA overnight.1 For inference-heavy workloads where cost matters, AMD can be the better choice. For training and maximum ecosystem support, NVIDIA leads.
Can ROCm replace CUDA?
CUDA is still the safer bet for production AI workloads. ROCm has made genuine progress—PyTorch runs well, MI300X benchmarks are competitive—but the ecosystem gap remains real.8
What’s the price difference between NVIDIA and AMD GPUs for AI?
CUDA leads by 18-27% in performance, but ROCm offers 20-40% cost savings for GPU computing.9 The gap depends heavily on specific workloads.
Should I wait for next-generation GPUs?
If you need compute now, rent on the cloud to avoid depreciation risk. If planning a hardware purchase, buy the current generation and plan to upgrade—waiting indefinitely means you never start.2
Is AMD ROCm production-ready in 2026?
ROCm has reached production-ready status for PyTorch and vLLM workloads in 2026. If your stack doesn’t depend on TensorRT-LLM or FlashAttention 3, AMD GPUs are worth benchmarking.16
The Bottom Line on NVIDIA vs AMD GPU for AI 2026
After testing both platforms extensively and talking to dozens of AI teams, here’s my honest conclusion about the NVIDIA vs AMD GPU for AI debate.
The real question isn’t NVIDIA vs AMD. It’s what you actually use your PC for, how long you plan to keep it, and whether you’d rather pay more upfront for flexibility or save money now and still get a great experience.6
NVIDIA still defines the standard. AMD is forcing choice back into the market.1
For the first time in years, you genuinely have options. That’s good news for everyone building AI applications.
My recommendation? Run your training experiments on ROCm to validate compatibility, keep CUDA as your production path8, and stay flexible. The competition between these two giants means better products and lower prices for all of us.
What’s your experience with NVIDIA or AMD GPUs for AI? Drop a comment below—I’d love to hear what’s working (or not working) for your team. And if you found this guide helpful, share it with someone wrestling with the same decision!